I wanted to learn more about MCP, so I’ve built an MCP server that adds regression analysis capabilities to AI models. Here, we’ll discuss what is MCP, why I chose linear regression, how to test an MCP server, and some limitations I currently see regarding the protocol and its implementations.
The repository is here: mcp-ols.
What is MCP?
Model context protocol (MCP), according to the official website, is:
[…] an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
It has been developed by Anthropic with the goal of providing a standardized interface for LLMs to interact with applications. They’ve also provided some reference servers that show how MCP servers can add various capabilities to LLMs, such as fetching web content or interacting with the local file system.
The host (an LLM-enabled application) starts an MCP client that maintains an 1:1 connection with the server. This connection happens through a transport layer, usually stdio but the specification also supports streamable HTTP transport. The stdio transport is suitable for running servers locally in your machine, and it’s the one we’ll use here. When running local MCP servers with stdio transport, the host will usually start the server process.
Linear regression is really useful
Ordinary least squares (OLS) regression is a simple yet unreasonably effective statistical model. To put it simply, it estimates the parameter of a linear equation of the form:
It’s easy to compute and easy to interpret. Each coefficient tells you how much is expected to change for each unit change in , all else being equal.
You may think this formulation is too restrictive, but bear with me.
Let’s say you have blood pressure data for two groups (treated or not) in a clinical trial, and you need to know whether the treatment had any effect.
It’s simple: run an OLS regression of the form blood_pressure ~ treatment, where treatment is a binary indicator.
This formula with ~ is a notation style from R that is very useful to specify a linear regression model.
It’ll be very useful here as an LLM-friendly way of creating regression models.
This example can be extended with multiple groups by adding dummy binary variables for each group value. Luckily, we don’t need to do this, as the formula notation allows us to specify categorical variables:
revenue ~ C(store) + temperature + C(dayofweek) + advertising_cost

The same OLS regression can be used to perform analyzes equivalent to other statistical methods such as ANOVA, correlation, and t-tests. It’s widely used in many areas of scientific research, finance, marketing, econometrics, among others. When you look closely, OLS is truly everywhere, mainly due to its interpretability and solid statistical foundation. Simple linear models often outperform experts despite their limitations, which is quite remarkable.
Adding statistical capabilities to LLMs
You can add an entire dataset (e.g. a CSV file) to a chat context and have the LLM analyze it, but extracting meaningful conclusions from raw CSV tokens is no easy feat. A common approach is to use the LLM to write code to analyze the data. This MCP server aims to be a middle ground, providing an interface to quickly analyze data using OLS — without adding the dataset to the chat context. It’s safer than allowing arbitrary code execution, but the real motivation is that I wanted to implement an MCP server.
The project was written in Python. Here is the repo. The official Python SDK provides some straightforward ways to build an MCP server, especially the FastMCP interface — not to be confused with the FastMCP library. Version 1.0 of FastMCP was incorporated into the mcp SDK, but since then both projects have apparently diverged a bit. Still, both are pretty similar.
We can define a bare-bones linear regression tool like this:
import numpy as np
import pandas as pd
from mcp.server.fastmcp import FastMCP
from statsmodels.api import formula as smf
mcp = FastMCP("linear-regression")
cache = []
@mcp.tool()
def run_ols_regression(formula: str):
"""Run a linear regression based on a patsy formula
Args:
formula: string of format Y ~ X_1 + X_2 + ... + X_n
"""
model = smf.ols(formula, cache[0]).fit()
return model.summary().as_html()The @mcp.tool decorator registers the function as a tool, extracting arguments and docstring.
We still have to read data into the “cache” list, though.
The quick and dirty solution was to create a session class to keep data and models:
class DataAnalysisSession:
def __init__(self):
self.sessions: dict[str, dict[str, Any]] = {}
def create_session(self) -> str:
session_id = str(uuid.uuid4())
self.sessions[session_id] = {
"data": None,
"metadata": {},
"models": {},
"created_at": datetime.now(),
}
return session_id
def get_session(self, session_id: str) -> dict[str, Any]:
if session_id not in self.sessions:
raise ValueError(f"Session {session_id} not found")
return self.sessions[session_id]
_session = DataAnalysisSession()Honestly, I find this a bit too ugly, as I dislike module-level global state. However, since each local MCP server session is started as a new process, this is not a big issue. In the case of remote MCP servers through streamable HTTP, this solution wouldn’t be appropriate.
Many MCP servers are stateless, which is arguably better considering that LLMs only have access to context, which may be detached from the MCP server state. The MCP documentation talks about replaying steps when using streamable HTTP mode, but this is beyond the scope of this project. The FastMCP framework is very convenient, but in my opinion both frameworks still have some rough edges, especially regarding testing.
The OLS part of the server is a simple wrapper around statsmodels, so there isn’t much relevant unit testing to be done.
I’ve then added some visualization tools, such as a residual plots tool, which return PNG image data using the Image type available both in mcp and FastMCP.
The image data is returned as a base64 encoded string to the client, and I’ve found that many MCP clients do not support image outputs yet. In these cases, the base64 string is added to the model context, which usually leads to the LLM trying to replicate the image data string without success.
Sending raw image data instead of the image itself to multimodal models also consumes much more tokens, often exceeding the maximum context length.
In its current form, the server contains tools to load data (of course), describe the data, run an OLS regression, and run a logistic regression1. Then, a set of tools to interpret models: plot residuals, test model assumptions, compute a VIF2 table, plot influence diagnostics, create partial dependence plots, list models, compare models, and plot model comparison. It should be able to read CSV, Excel, JSON, and parquet files, as well as tables from SQLite databases.
Using the MCP server
I recommend using Claude Desktop, since it’s probably the most polished MCP client experience. Unfortunately, it’s not available on Linux yet, so I have not used it here. You may add the MCP server using a CLI/GUI of your choice (e.g. the claude CLI), or you may edit a JSON configuration file directly. Below is an example in the style of Claude Desktop:
{
"mcpServers": {
"mcp-ols": {
"command": "uvx",
"args": ["mcp-ols"]
}
}You can copy the mcp-ols part and paste it in most applications with MCP support, including VS Code.
We’re using uv to run the MCP, so you should install it first.
Activate the MCP server in a new chat and then ask it to analyze some data file. I’ll use the Advertising dataset from chapter 2 of ISLR3, which can be found here. The LLM should then be able to use the tools to load, analyze the data, and run regression models.
Chat example
I’ve omitted tool calls and filler text.
Let’s analyze the data in ~/Documents/Advertising.csv
[…] Here’s a summary of your Advertising dataset […]
Yes, let’s run a regression on sales
Here are the results of the linear regression predicting Sales from advertising spend on TV, Radio, and Newspaper:
R-squared: 0.897 (89.7% of the variance in Sales is explained by the model) Adjusted R-squared: 0.896 F-statistic: 570.3, p-value: <0.001 (model is highly significant) Coefficients:
Intercept: 2.94 TV: 0.0458 (highly significant, p < 0.001) Radio: 0.1885 (highly significant, p < 0.001) Newspaper: -0.0010 (not significant, p = 0.86) Interpretation:
TV and Radio advertising both have a strong, statistically significant positive effect on Sales. Newspaper advertising appears to have no significant impact on Sales in this model.
Try some models with interactions and compare them
[…]
| Model | Formula | R-squared | Adj. R² | AIC | Significant interactions? |
|---|---|---|---|---|---|
| 1 | Sales ~ TV + Radio + Newspaper | 0.897 | 0.896 | 780.4 | None |
| 2 | Sales ~ TV + Radio + Newspaper + TV:Radio | 0.968 | 0.967 | 550.1 | TV:Radio (very significant) |
| 3 | Sales ~ TV + Radio + Newspaper + TV:Newspaper | 0.903 | 0.901 | 769.8 | TV:Newspaper (significant) |
| 4 | Sales ~ TV + Radio + Newspaper + Radio:Newsp | 0.897 | 0.895 | 781.9 | Radio:Newspaper (not significant) |
| 5 | Sales ~ TV _ Radio _ Newspaper (all inter.) | 0.969 | 0.968 | 550.9 | Only TV:Radio |
Key findings:
- Adding the TV:Radio interaction (Model 2) gives a big boost to R² and AIC, indicating a much better fit. The interaction is very significant (p < 0.001).
- Adding TV:Newspaper (Model 3) gives a small boost; the interaction is significant, but the increase in fit is limited.
- Adding Radio:Newspaper (Model 4) does not improve the model.
- The full interaction model (Model 5) has the highest R² (marginally above Model 2) and the lowest AIC, but only TV:Radio remains highly significant. The additional interaction terms are not significant.
Conclusion:
- The best balance of model fit and simplicity is Model 2 (with the TV:Radio interaction).
- Model 5 is technically “best” on R²/AIC, but the extra interaction terms do not contribute much and add unnecessary complexity.
- Most important features for predicting Sales: TV, Radio, and their interaction.
I’ve also asked it to plot residuals and analyze the plots. If you use a multimodal model, it should be able to interpret the plots. The tool call returned the following image:
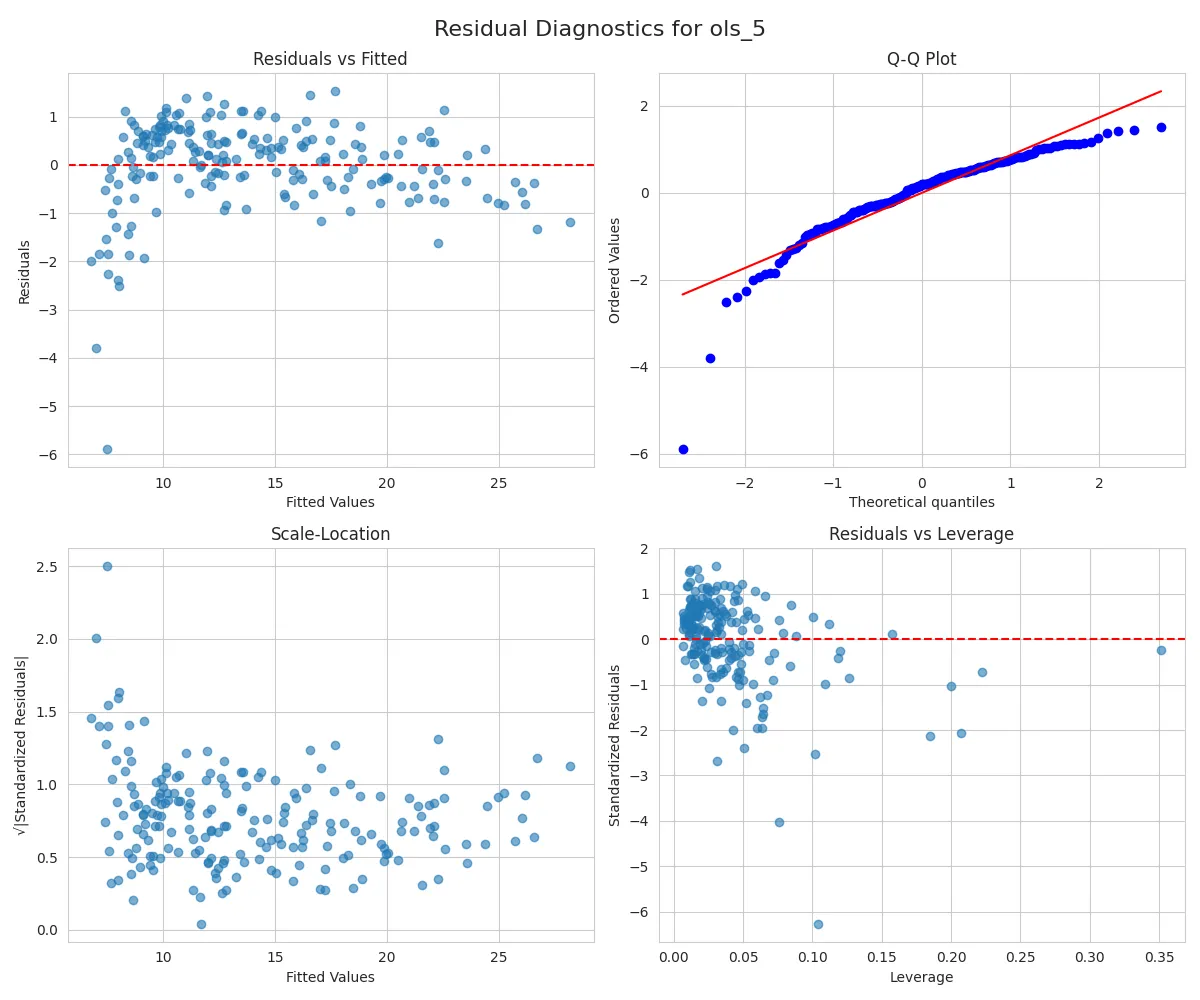
This is a simple example, but you can use this MCP server to experiment with more complex datasets, compare models, check assumptions, plot partial regressions, and so on.
Testing
From what I’ve gathered, I see three major ways to write automated tests for MCP servers. The first is the usual unit testing. This project is a thin wrapper around statsmodels and matplotlib, so even though it would be possible to write unit tests, they were not my focus. I think unit tests here are better suited for functions that tools call in more complex scenarios and for checking tool input validation.
The second way of testing is using tool calls directly, with the server running in-memory. This is the approach I’ve used here with the FastMCP library. However, this is prone to test pollution — that is, a test may fail due to the side-effects of other tests on the server state. The MCP server instance is a module-level global variable, hence all tests share the same MCP server state. I’ve tried creating the server instance and adding tools dynamically in a main function, but it was very clunky and, more importantly, it broke the MCP inspector integration.
The MCP inspector is an interactive developer tool for testing and debugging MCP servers through a web interface, which is quite useful. Alas, the tests share global state.
The third way of testing is end-to-end testing, in which you create instantiate a new client-server pair for each test. For instance, if we wanted to list all available tools, we could implement something like this:
async def main():
server_params = StdioServerParameters(command="python", args=["mcp_ols.py"])
async with stdio_client(server_params) as (read_stream, write_stream):
async with ClientSession(read_stream, write_stream) as session:
await session.initialize()
tools_result = await session.list_tools()
for tool in tools_result.tools:
print("=" * 50)
print(f"{tool.name}: {tool.description}")This example, unlike the final code in the repository, uses the mcp library instead of FastMCP4. This idea can be used to write end-to-end tests, but each test will start a new process (using Python’s multiprocessing) for the MCP server instance, which is quite slow. In production settings, I think tests like this would be a good call, but not for our small project.
Thoughts on MCP
There is a running debate over MCP versus CLI tools.
The MCP protocol provides a standardized interface to add tools to the context of AI models, which can then decide to call these tools.
The alternative is letting the AI model call CLI utilities (e.g. git, jq) directly through shell commands or custom scripts.
Armin Ronacher, for instance, argues that MCP relies too much on inference and demands too much context. The idea is that using CLI tools or writing scripts is more composable and, crucially, more reusable and verifiable when automating tasks (I highly recommend reading his post, this is a very short summary). Overall, I think Armin has a valid point. When tool count is high, model performance on tasks that require tools degrades. Sometimes, the model will simply not use the correct tools, and you need to nudge it towards the right direction, which consumes more context. I also agree that you can go a long way with CLI tools (e.g. the GitHub CLI).
Nonetheless, I see some limitations in the CLI/script approach. First, many clients do not have shell access to execute commands or scripts, and executing arbitrary scripts can be dangerous. Right now I think the overlap between tech-savvy people and Claude Desktop users (the most popular MCP client) is very high, so most MCP users would likely be able to evaluate the safety of shell commands and simple scripts. If the idea of tool-calling with LLMs becomes more widespread, then this issue would be more relevant. Safety can be built into MCP servers, but they’re still processes running with arbitrary permissions — you have to trust the MCP server to have implemented all the necessary guardrails. Maybe we’ll figure out how to sandbox these tools, or we’ll just keep asking the user for confirmation on each tool call.
When the task requires long-running state, MCP also has an advantage.
In mcp-ols, the CLI approach would have to reload the data at every call (but it would still work).
All tools in our server can be implemented through simple scripts, and in some way it is a collection of scripts transformed into a server.
Right now, I wouldn’t use this simple server to automate tasks at scale.
I see it more as a pre-made collection of functions that perform one task well enough to be reused in local-first settings.
You can quickly ask the AI model to perform regression analysis because the code has already been written and encapsulated into the MCP server.
There are still some rough edges on MCP servers and clients, especially clients. I’ve tested various clients and they had very different behaviors. Some would not include the output of tool calls in the chat context (they included only the remarks of the LLM regarding the output). This renders our server unusable. Most did not handle images returned by the server well, adding them as raw base64 strings to the context. This, of course, consumes a lot of tokens and provides no information to the LLM. Since it’s still a new standard, this is expected. There is a huge number of AI models and providers and not all are multimodal. For what I’ve seen, multimodality is also a sharp edge for now.
Conclusions
Building this simple MCP server was very interesting. I thought it would be a rather boring project, but besides learning about MCP it made me reflect about LLM tool-calling, how to test such tools, and the safety of arbitrary tool calling. It was also an excuse for me to try many interesting open-source MCP clients. Unfortunately, Claude Desktop is still not available on Linux, but I hope this changes soon. I’ll continue to try out some MCP servers and see how they can improve my workflows.
Footnotes
-
Logistic regression is not an OLS model, but it’s common enough to be included here. ↩
-
Variance inflation factor (VIF) is used as an indicator of multicollinearity. ↩
-
An Introduction To Statistical Learning — James et al. ↩
-
I was trying out both libraries, so at each point I was using one. It’s part of working on new things, I guess. ↩