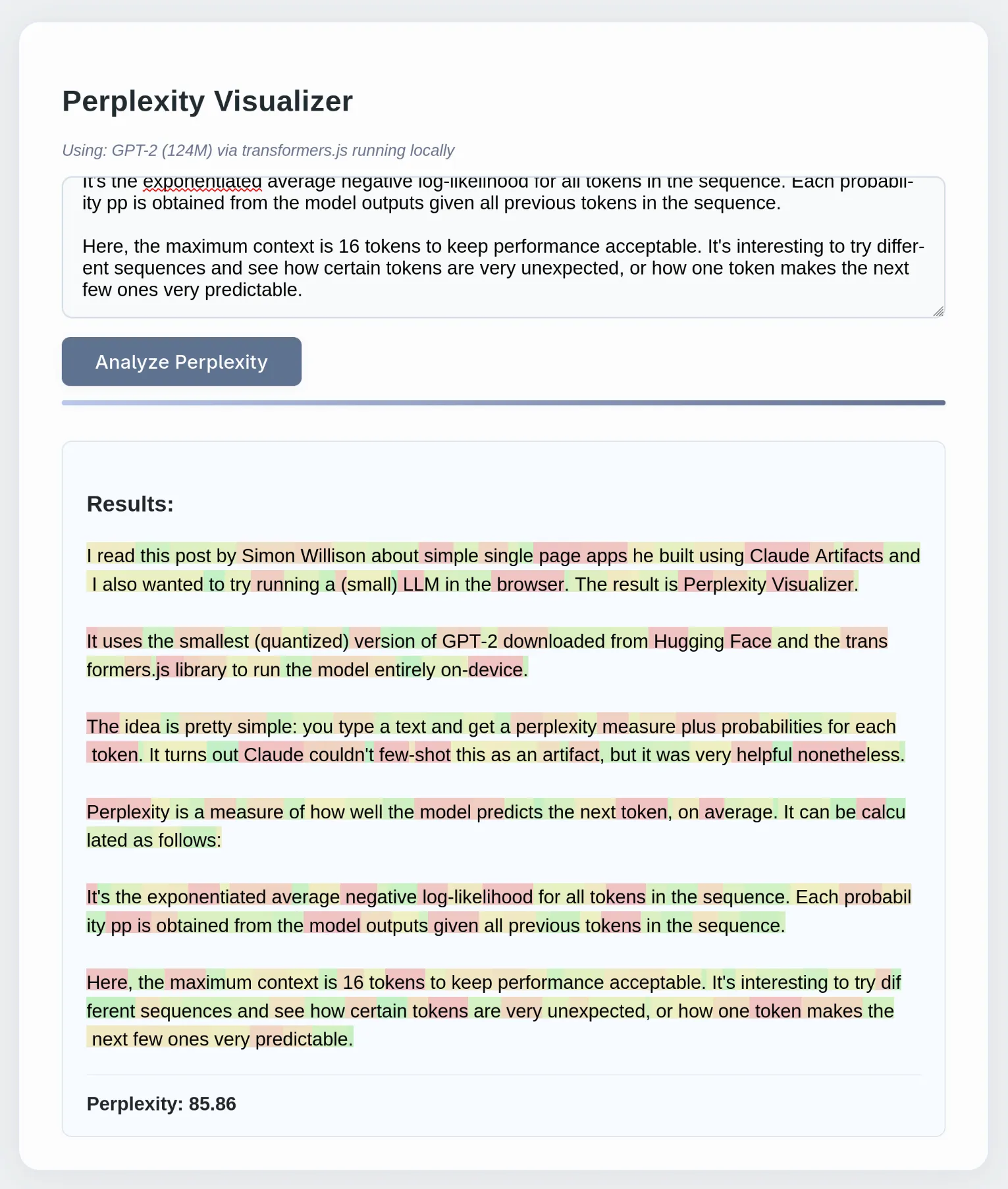
I read this post by Simon Willison about simple single page apps he built using Claude Artifacts and I also wanted to try running a (small) LLM in the browser. The result is Perplexity Visualizer.
Be warned: opening the link will download the model (over 100 MB)
It uses the smallest (quantized) version of GPT-2 downloaded from Hugging Face and the transformers.js library to run the model entirely on-device.
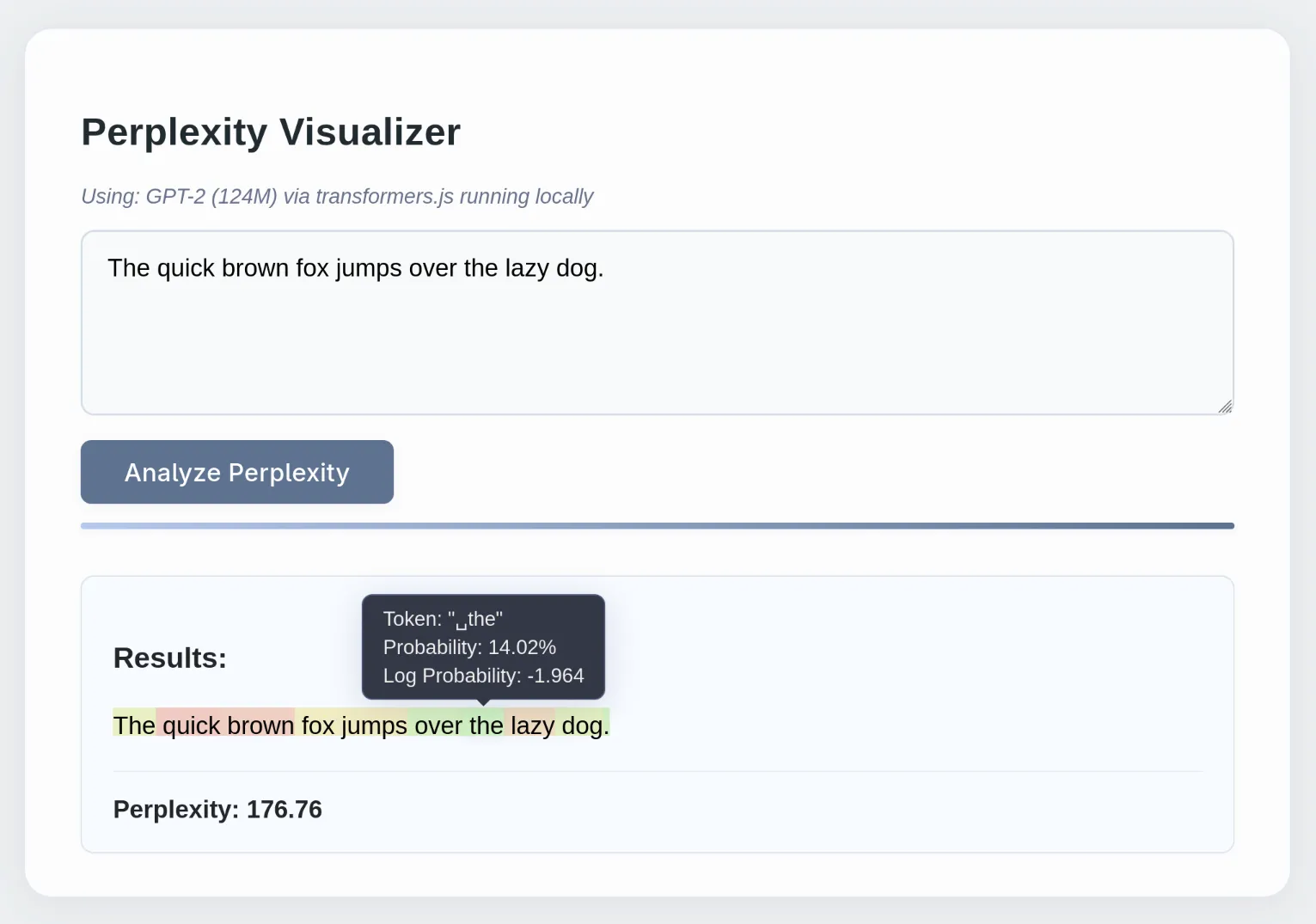
The idea is pretty simple: you type a text and get a perplexity measure plus probabilities for each token. It turns out Claude couldn’t few-shot this as an artifact, but it was very helpful nonetheless.
Perplexity is a measure of how well the model predicts the next token, on average. It can be calculated as follows:
It’s the exponentiated average negative log-likelihood for all tokens in the sequence. Each probability is obtained from the model outputs given all previous tokens in the sequence.
Here, the maximum context is 16 tokens to keep performance acceptable. It’s interesting to try different sequences and see how certain tokens are very unexpected, or how one token makes the next few ones very predictable.
Here is the output using the text of this post: